How to Upload Folder Into Sagemaker Jupyter Notebook
From local Jupyter Notebooks to AWS Sagemaker.
I will be covering the nuts and a generic overview of what are the basic services that you'd need to know for the certification, We will not exist covering deployment in particular and a tutorial of how you might exist able to use these services in this guide.

Now earlier you recollect almost Machine Learning Specialty certification from AWS, if you oasis't washed whatever certification from AWS before I will suggest you to complete AWS Cloud Practitioner.
Getting through the Deject Practitioner is relatively like shooting fish in a barrel and you will get perks. Perks like a free practice test of the next certification of your choice and 50 per centum discount on y'all next certification exam.
There are certain central points before you embark on your journeying for the Automobile Learning Specialty certification:
- Information technology is recommended that you accept 1 to ii years of feel of using AWS for ML projects and pipelines
- It is recommended for people who have relative expertise over manipulating Data sets, doing EDA, extraction, tuning etc.
- This exam is specifically built to weed out people who don't have an analytics background and don't have an in depth understanding of how Auto Learning pipelines work.
- It is my personal stance that you at least understand using shell commands, Docker containers and model deployment to fully grasp the SageMaker services and pipelines.
I volition be dividing the modules into few parts and my key focus will exist on the SageMaker part of the certification because that alone could get yous through the examination if y'all are very good at it.
Understanding AWS storage
For our certification we will exist sticking to S3 but information technology's recommended to have a minimum idea of other storage services.
Amazon Simple Storage Service or S3 stores information equally objects within buckets
- You can set private permissions(create, delete, view list of objects) for every bucket inside S3
- S3 has 3 different storage classes: S3 Standard — Full general purpose storage for whatsoever type of data, typically used for oftentimes accessed data, S3 Intelligent — Tiering * — Automated toll savings for data with unknown or changing access patterns, S3 Glacier ** — For long-term backups and athenaeum with retrieval option from 1 minute to 12 hours. S3 standard being the about expensive.
- For our preparation purposes we tin can both provide them as split channels using S3 buckets, we will get into more details later on while we get through the inbuilt algorithms.
- For writing and reading data using S3 you demand to use boto3 framework which is preinstalled on the sagemaker note volume instances.
For a better understanding of the S3 storage and availability, you lot can utilize the following link: https://aws.amazon.com/s3/storage-classes/
Jupyter notebooks: You could launch a jupyter notebook direct from an EC2 case simply you're responsible for the following things:
- Creating the AMI(Amazon car image, in short the OS)
- Launching those instances with this AMI.
- Configuring the autoscaling options depending on the task.
However, it's very straight forward, yous just need the ssh key pair piece of work and add the device IP from which you are connected to the security group of the EC2 example you are trying to connect. If you lot use this service you volition have to have care of the Container registry, the endpoints, distribution of Training jobs and the tuning as well. The major advantage of using Sagemaker is that it manages all these things for yous.
Allow's drive straight into AWS Sagemaker, we volition cover some key concepts in depth as we try to understand the various components.
Sagemaker is a fully managed service by AWS to build, train and deploy car Learning models at calibration.
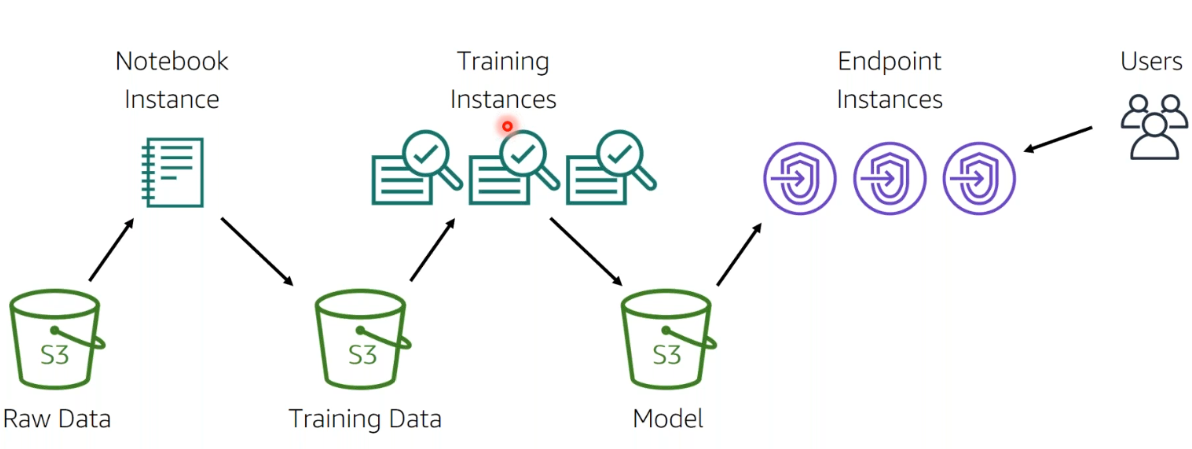
Edifice pipelines in Sagemaker:
You tin can read data from S3 in the following ways:
- Directly connect to S3
- Using AWS Glue to move data from Amazon RDS, Amazon DynamoDB, and Amazon Redshift into S3.
Grooming on AWS Sagemaker:
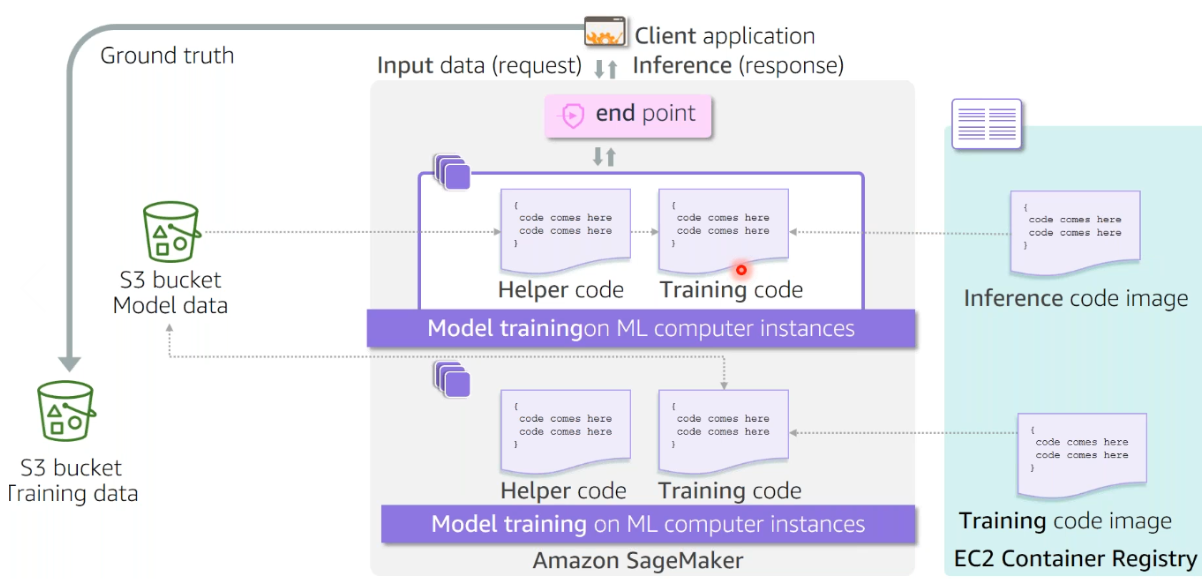

Nosotros will be covering the inbuilt algorithms in this part.
Trending AI Articles:
1. Automobile Learning Concepts Every Data Scientist Should Know
ii. AI for CFD: byteLAKE's approach (part3)
three. AI Fail: To Popularize and Scale Chatbots, Nosotros Need Better Data
iv. Top 5 Jupyter Widgets to heave your productivity!
Just as you lot need the ingredients to cook a dish, A Sagemaker preparation job needs these key components:
- Training information S3 bucket URL(Think, this must exist globally unique!)
- What type of ML case exercise yous need for this task:
ml.t2.medium — ml stands for motorcar learning, the next department can exist divers from the following table:

Apart from these instances you lot also have g4dn, inf1 instances that tin be used for training
environmental impact assessment instances can be used for just for inference.
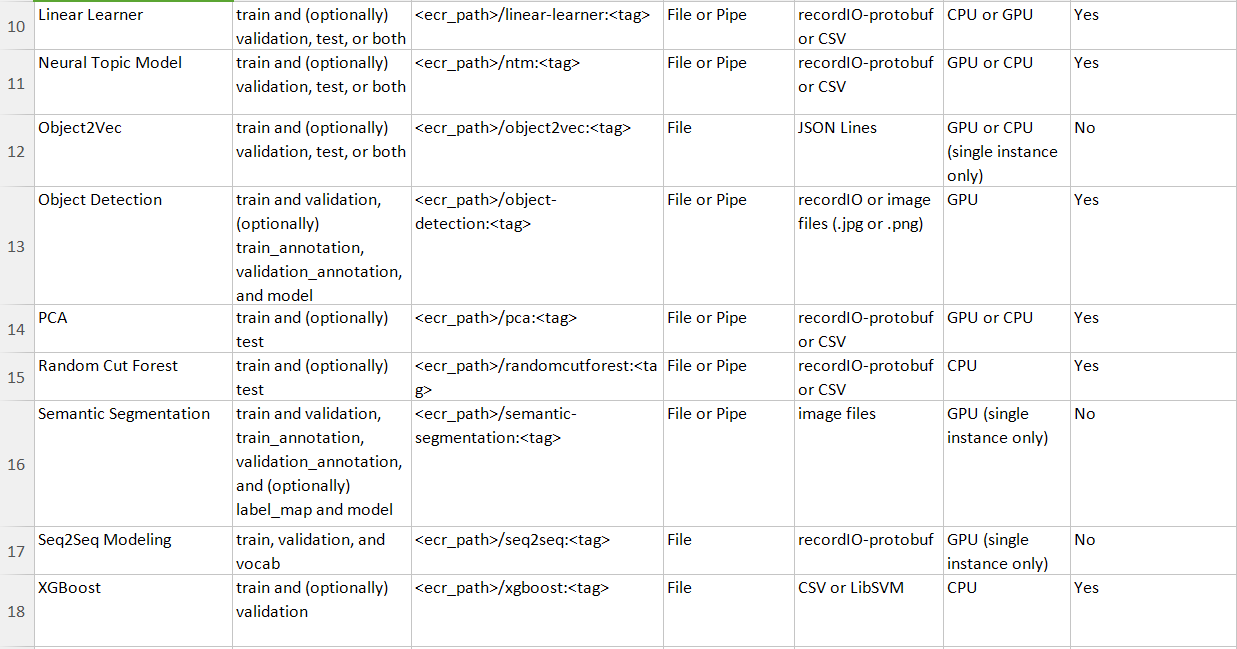
Choosing the right Training Algorithm
Once you accept decided on the instance types to use for the notebook, you accept the choice of following algorithms available already from AWS or utilise your ain algorithm, nosotros volition cover that later:
Refer these tree diagrams for an easy recall.
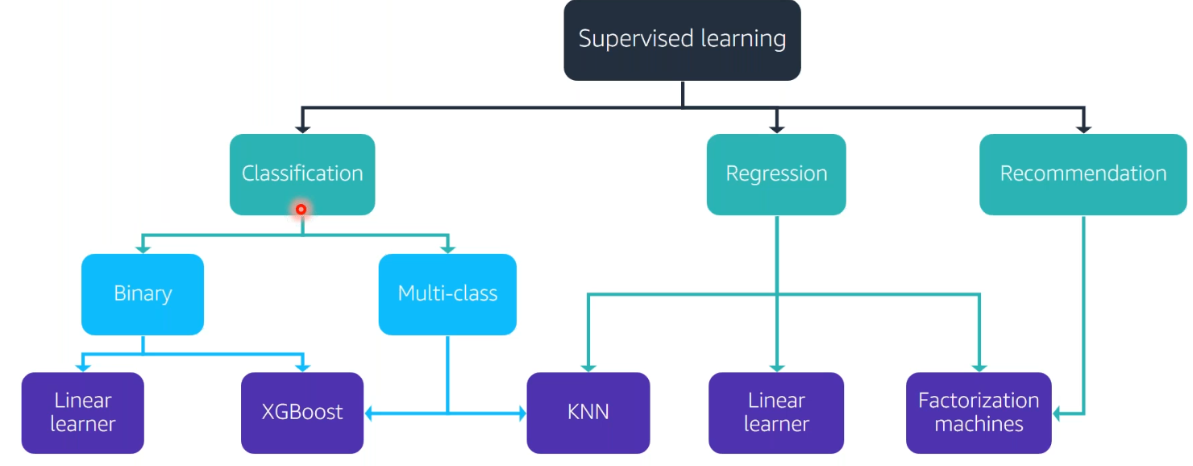
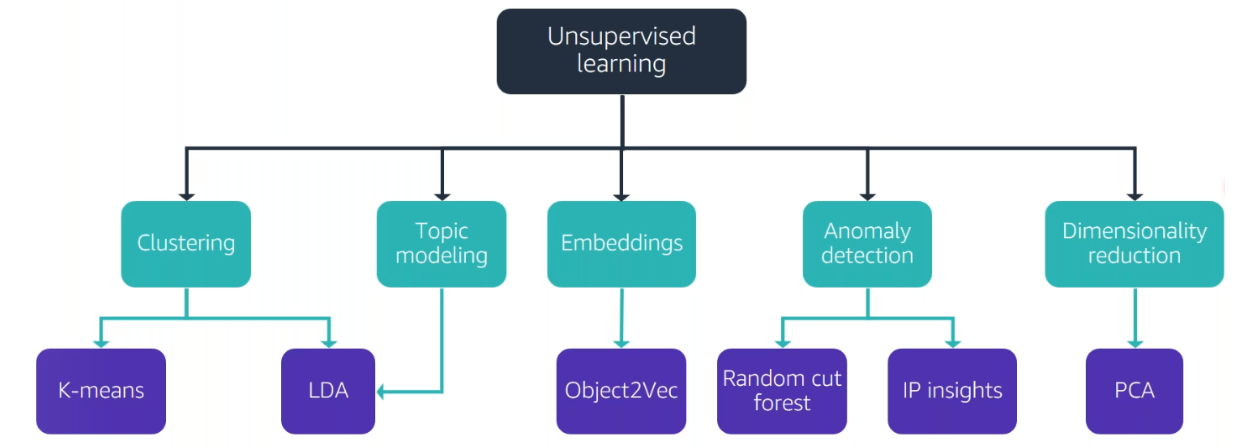
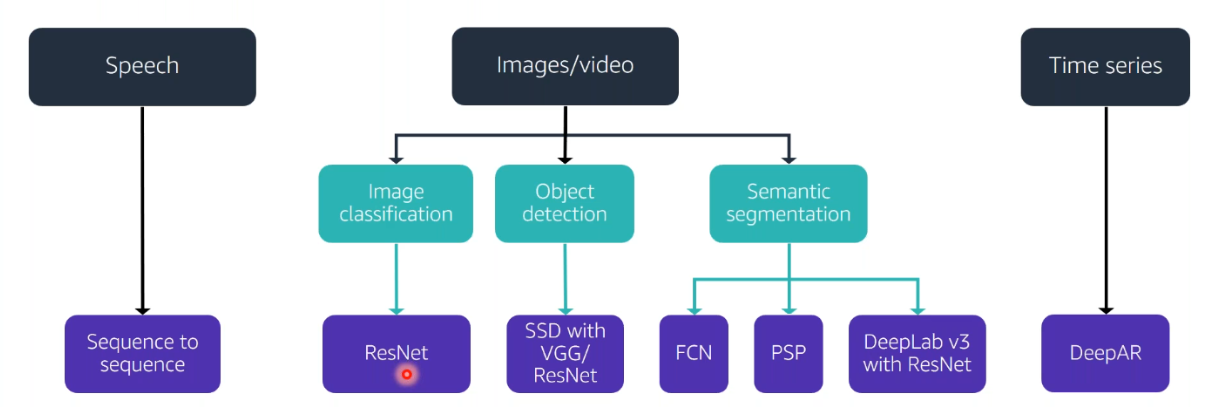
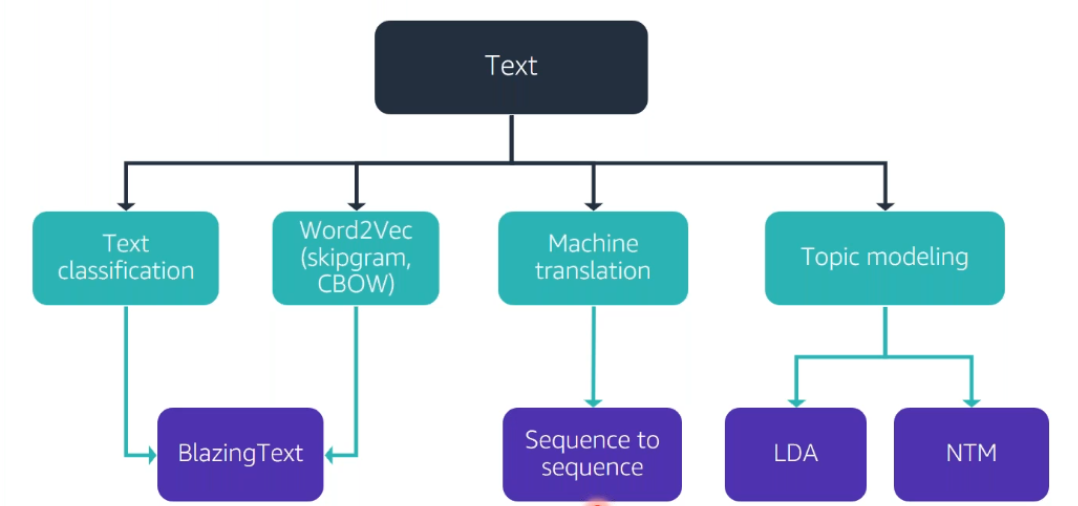
These include the parameters that are accustomed for most of these algorithms(Tip! You lot might want to call up them)
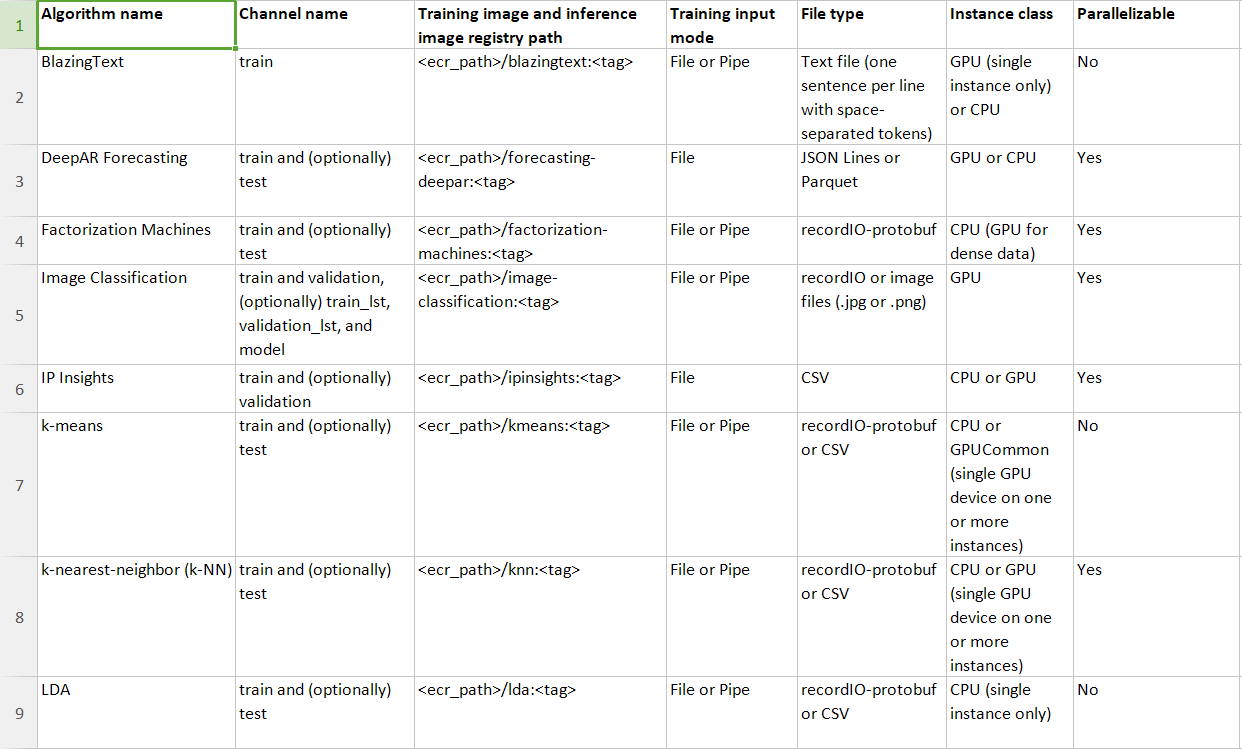
Transforming the Training Information
Afterwards you lot accept launched a notebook, yous need the post-obit libraries to be imported, we're taking the example of XGboost here:
import sagemaker
import boto3
from sagemaker.predictor import csv_serializer # Converts strings for HTTP Mail service requests on inferenceimport numpy as np # For performing matrix operations and numerical processing
import pandas as pd # For manipulating tabular data
from fourth dimension import gmtime, strftime
import osregion = boto3.Session().region_name
from sagemaker import get_execution_role
smclient = boto3.Session().client('sagemaker')
# the IAM role that you created when you created your #notebook example. You laissez passer the role to the tuning job.part = get_execution_role()
saucepan = 'sagemaker-MyBucket'
print(function)
#supplant with the name of your S3 bucket
prefix = 'sagemaker/DEMO-automatic-model-tuning-xgboost-dm'
Adjacent Download the data and exercise EDA.
Hyperparameter Tuning
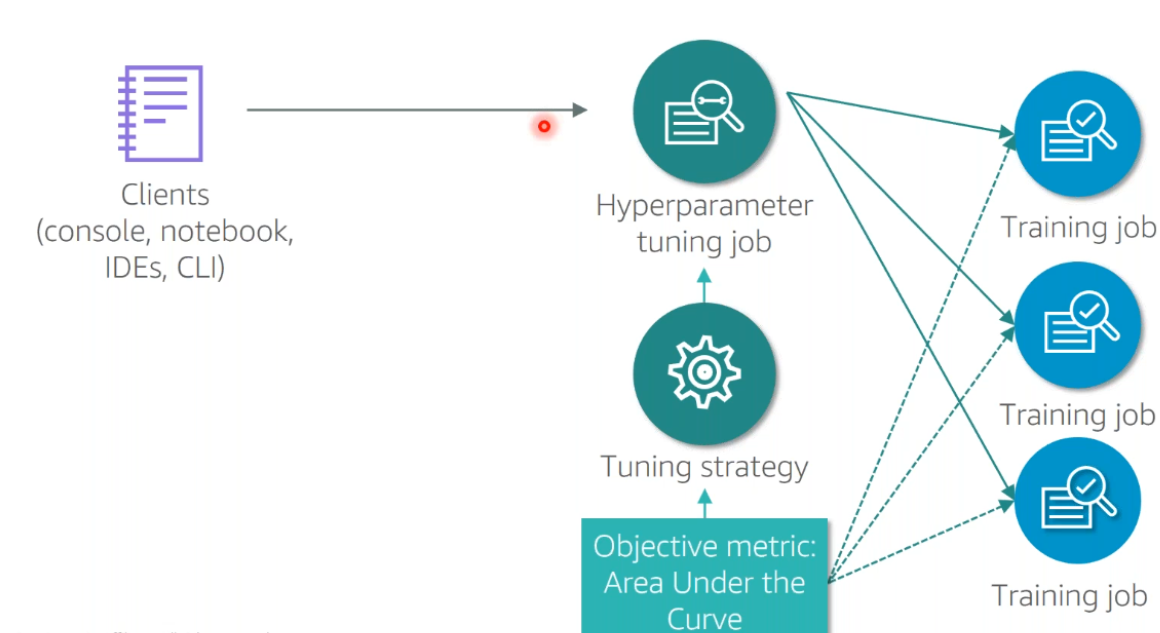
Hyperparameter tuning job specifications tin be found here
from sagemaker.amazon.amazon_estimator import get_image_uri
training_image = get_image_uri(boto3.Session().region_name, 'xgboost')s3_input_train = 's3://{}/{}/train'.format(bucket, prefix)
training_job_definition = {
s3_input_validation ='s3://{}/{}/validation/'.format(bucket, prefix)
tuning_job_config = {
"ParameterRanges": {
"CategoricalParameterRanges": [],
"ContinuousParameterRanges": [
{
"MaxValue": "1",
"MinValue": "0",
"Name": "eta"
},
{
"MaxValue": "ii",
"MinValue": "0",
"Name": "blastoff"
},
{
"MaxValue": "ten",
"MinValue": "i",
"Proper name": "min_child_weight"
}
],
"IntegerParameterRanges": [
{
"MaxValue": "10",
"MinValue": "1",
"Name": "max_depth"
}
]
},
"ResourceLimits": {
"MaxNumberOfTrainingJobs": twenty,
"MaxParallelTrainingJobs": 3
},
"Strategy": "Bayesian",
"HyperParameterTuningJobObjective": {
"MetricName": "validation:auc",
"Type": "Maximize"
}
}
"AlgorithmSpecification": {
"TrainingImage": training_image,
"TrainingInputMode": "File"
},
"InputDataConfig": [
{
"ChannelName": "railroad train",
"CompressionType": "None",
"ContentType": "csv",
"DataSource": {
"S3DataSource": {
"S3DataDistributionType": "FullyReplicated",
"S3DataType": "S3Prefix",
"S3Uri": s3_input_train
}
}
},
{
"ChannelName": "validation",
"CompressionType": "None",
"ContentType": "csv",
"DataSource": {
"S3DataSource": {
"S3DataDistributionType": "FullyReplicated",
"S3DataType": "S3Prefix",
"S3Uri": s3_input_validation
}
}
}
],
"OutputDataConfig": {
"S3OutputPath": "s3://{}/{}/output".format(bucket,prefix)
},
"ResourceConfig": {
"InstanceCount": two,
"InstanceType": "ml.c4.2xlarge",
"VolumeSizeInGB": 10
},
"RoleArn": part,
"StaticHyperParameters": {
"eval_metric": "auc",
"num_round": "100",
"objective": "binary:logistic",
"rate_drop": "0.3",
"tweedie_variance_power": "1.iv"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 43200
}
} tuning_job_name = "MyTuningJob"
smclient.create_hyper_parameter_tuning_job(HyperParameterTuningJobName = tuning_job_name,
HyperParameterTuningJobConfig = tuning_job_config,
TrainingJobDefinition = training_job_definition)
Monitoring can be done directly on the AWS console itself

Evaluating is very straight forward,Y'all apply a Jupyter notebook in your Amazon SageMaker notebook example to train and evaluate your model.
- You lot either use AWS SDK for Python (Boto) or the high-level Python library that Amazon SageMaker provides to send requests to the model for inferences.
How to Debug?
Say hello to the Amazon SageMaker Debugger!
Information technology provides full visibility into model training past monitoring, recording, analyzing, and visualizing training procedure tensors. Using Amazon SageMaker Debugger Python SDK we can interact with objects that will assistance us debug the jobs. If you are more interested in the api, y'all can check it out here.
You tin check the list of rules here.
Deploying the model
- After I created a model using createmodel api. Speicify S3 path where the model artifacts are stored and the Docker registry path for the prototype that contains the inference lawmaking.
- Create an HTTPS endpoint configuration i.east: Configure the endpoint to elastically scale the deployed ML compute instances for each production variant job, for further details most the API, cheque CreateEndpointConfig api.
- Adjacent launch information technology using the CreateEndpoint api
I volition discuss more near the details of deployment in the side by side function.
Don't forget to give usa your 👏 !
Source: https://becominghuman.ai/from-local-jupyter-notebooks-to-aws-sagemaker-b4a792f5d270
0 Response to "How to Upload Folder Into Sagemaker Jupyter Notebook"
Post a Comment